In February 2025, Andrej Karpathy posted a reflection on X that resonated widely across the programming community1:
“There’s a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model…”
That is a lot of concepts. Agents, subagents, prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations — the list reads like a parts catalog for a machine whose blueprints nobody has published.
For a physicist, this profusion of concepts is disorienting but also familiar. We have seen it before: a new domain presents a bewildering zoo of phenomena, and the first instinct is to search for the small set of principles that governs the whole zoo. In thermodynamics, two laws — plus a zeroth — suffice to generate an entire field. Can we find something similar here?
I believe we can. There are two empirical constraints that, taken together, explain most of the architectural choices in modern agent systems and bring order to Karpathy’s daunting list. I call them the First Law and the Second Law — not because they carry the certainty of thermodynamics, but because they play an analogous role: they define the boundary conditions within which all agent engineering must operate.
1. The First Law: Better Prompts, Better Outputs
The First Law is deceptively simple:
The performance of large language models improves as prompts become more refined.
This has been demonstrated repeatedly since the earliest days of modern LLMs. When Brown et al. introduced GPT-3 in 2020, one of the paper’s most striking findings was the scaling of in-context learning2. Given a classification task, for instance, a model’s accuracy improved monotonically as the number of demonstration examples increased:
- Zero-shot (task description only): the model guesses based on pre-trained knowledge alone.
- One-shot (one labeled example): accuracy jumps noticeably.
- Few-shot (several examples): accuracy continues to climb, often approaching fine-tuned performance.
The pattern extends well beyond simple classification. Wei et al. showed that by adding a chain-of-thought (CoT) instruction — essentially telling the model to “think step by step” — reasoning accuracy on math and logic problems improved dramatically, particularly for larger models3. This is not more data in the traditional sense; it is a more refined structure within the prompt that guides the model’s computation.
Retrieval-Augmented Generation (RAG) industrializes this principle4. Instead of hoping the model memorized the answer during pre-training, a RAG system retrieves relevant documents at query time and injects them into the prompt. The model sees exactly the information it needs, and the output quality improves accordingly.
 Fig. 1 Schematic illustration of the First Law: task accuracy improves monotonically as prompts become more refined, from zero-shot through few-shot to retrieval-augmented generation.
Fig. 1 Schematic illustration of the First Law: task accuracy improves monotonically as prompts become more refined, from zero-shot through few-shot to retrieval-augmented generation.
The implication for agent systems is direct: an agent’s primary job is to engineer the prompt on behalf of the user. When you ask a coding agent to fix a bug, the agent does not simply forward your request to the LLM. It searches the codebase for relevant files, reads them, identifies the error context, and constructs a prompt that contains precisely the information the model needs to produce a correct fix. The user typed one sentence; the agent built a richly-structured, evidence-laden prompt behind the scenes.
This is the First Law at work — the relentless drive to put the right information in front of the model.
2. The Second Law: Context Windows Have Diminishing Returns
The Second Law provides the counterweight:
The performance of large language models degrades as the context window expands with irrelevant or loosely-relevant material.
If the First Law were the only constraint, the optimal strategy would be trivial: dump everything into the context window. Every file in the repository, every document in the knowledge base, every prior conversation — pack it all in. But empirically, this fails.
The most vivid demonstration is the needle-in-a-haystack experiment, first popularized by Kamradt in 20235. The setup is simple: insert a specific fact (the “needle”) at various positions within a long document (the “haystack”), then ask the model to retrieve it. The result is striking — as the haystack grows, the model’s ability to find the needle degrades, and the degradation is position-dependent: facts placed in the middle of the context are retrieved less reliably than those at the beginning or end.
Liu et al. formalized this observation in their paper Lost in the Middle6. Across multiple models and tasks, they found a consistent U-shaped attention pattern: models attend most strongly to the beginning and ending of the input, with a “valley” of reduced attention in the middle. This means that naively stuffing more information into the context can actually hurt performance — the relevant information gets lost among the noise.
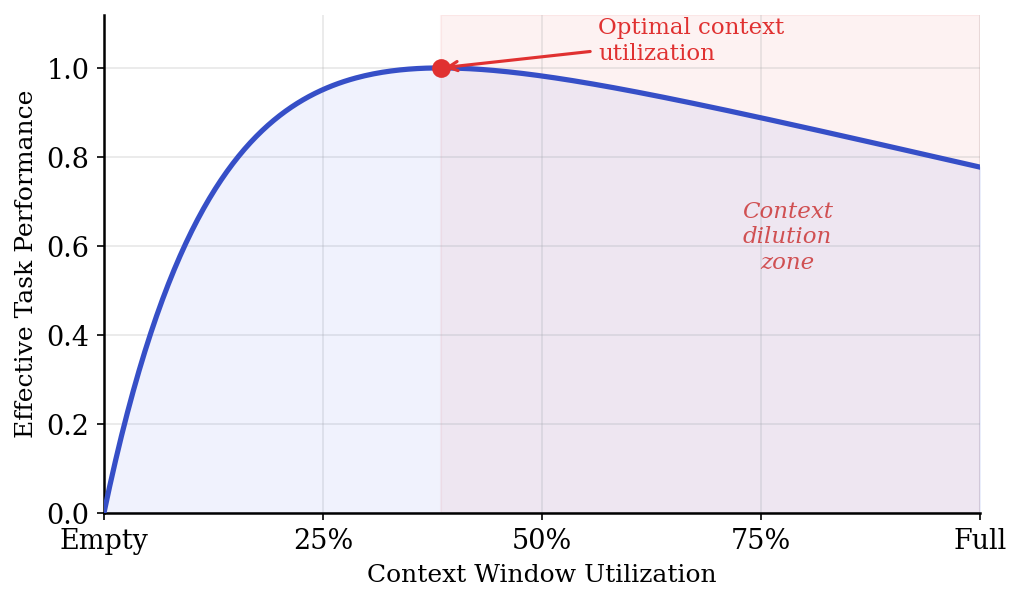 Fig. 2 Schematic illustration of the Second Law: effective task performance peaks at moderate context utilization and degrades as the window fills with low-relevance material.
Fig. 2 Schematic illustration of the Second Law: effective task performance peaks at moderate context utilization and degrades as the window fills with low-relevance material.
Think of it as a signal-to-noise problem. The “signal” is the information the model needs to answer the query; the “noise” is everything else in the context. Adding more relevant signal helps (First Law). But adding context indiscriminately increases noise faster than signal, and the model’s effective attention — its ability to focus on what matters — dilutes (Second Law).
This is not merely a temporary limitation to be solved by longer context windows. Even as context lengths have grown from 4K to 128K to 1M tokens, the fundamental attention-dilution effect persists7. Longer context windows expand the capacity, but they do not eliminate the cost of filling that capacity with low-relevance material.
3. Agent Architecture: Reconciling the Two Laws
Here lies the central tension of agent system design:
- The First Law says: give the model as much relevant information as possible.
- The Second Law says: do not bloat the context with irrelevant material.
The resolution is hierarchical, on-demand context management — a layered system where information is organized by relevance and loaded only when needed.
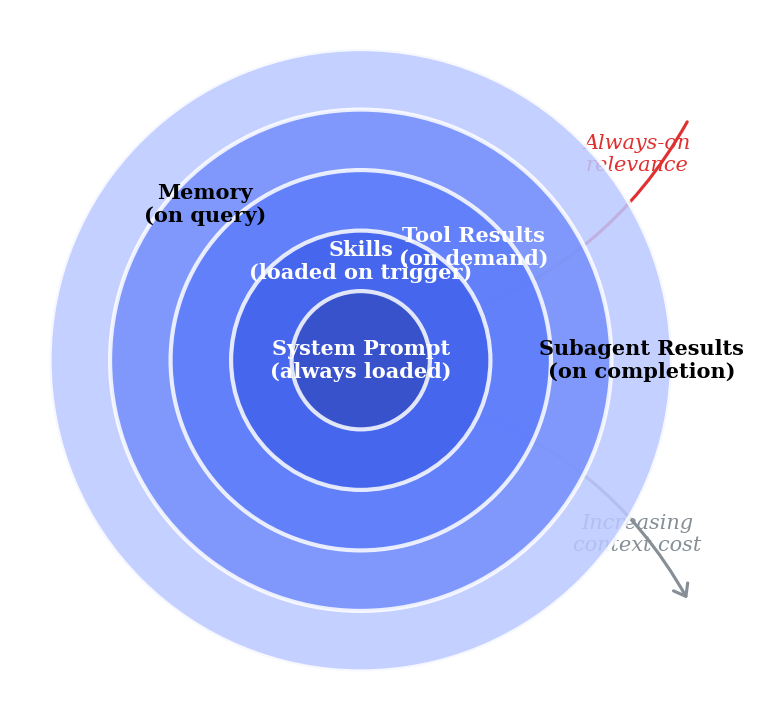 Fig. 3 Hierarchical context architecture. Inner layers are always present and compact; outer layers are loaded on demand and carry higher context cost.
Fig. 3 Hierarchical context architecture. Inner layers are always present and compact; outer layers are loaded on demand and carry higher context cost.
Modern agent systems implement this through several concrete mechanisms.
3.1 System Prompts
The innermost layer. A system prompt is always loaded into every LLM call. Because it is always present, it must be compact and high-value: role definitions, safety constraints, output formatting rules, and core behavioral instructions. A well-designed system prompt is typically a few hundred to a few thousand tokens — small enough to never be a burden, important enough to never be omitted.
3.2 Skill Files
The next layer out. A skill file (such as a SKILL.md in the Copilot agent ecosystem) encapsulates domain-specific knowledge for a particular type of task — how to write tests, how to format blog posts, how to design APIs. Crucially, skills are loaded on trigger: the agent detects that the user’s request matches a skill’s domain and reads the file at that point, rather than keeping all skills in context permanently. This is a direct application of the two-law tradeoff: the skill’s content dramatically improves prompt quality (First Law) while its on-demand loading avoids context bloat (Second Law).
3.3 Tool Use and Model Context Protocol (MCP)
Rather than embedding tool documentation or external data into the context, modern agents let the model call tools on demand89. Need to search the codebase? Call a grep tool. Need to read a file? Call a read tool. Need to check compiler errors? Call a diagnostics tool. Each tool call returns only the specific information requested, not an entire knowledge base.
The Model Context Protocol (MCP) standardizes this further: external services expose their capabilities as callable tools, and the agent invokes them as needed10. The context grows only by the size of each tool’s result, and only when the model decides that result is needed.
3.4 Memory Systems
Agent memory provides persistent context without permanent context occupation. A well-designed memory system uses tiers:
- User memory: long-lived preferences and patterns that persist across sessions. Loaded automatically but kept brief.
- Session memory: task-specific notes for the current conversation. Created on demand, discarded when the session ends.
- Repository memory: project-scoped facts about conventions, build commands, and architecture. Stored locally, queried when relevant.
Each tier trades off persistence against context cost. User memory is always partially loaded (a few hundred tokens), while session and repo memory are queryable — the agent reads them only when the task demands it.
3.5 Subagents
The most dramatic context management strategy: delegate subtasks to fresh-context workers. When an agent faces a complex, multi-step task, it can spawn a subagent with a focused prompt and a clean context window. The subagent performs its work — searches, reads files, makes a decision — and returns a concise summary to the parent agent.
This is powerful because it resets the context. The parent agent’s context is not burdened by the intermediate search results, false starts, and exploration that the subagent performed. Only the distilled result comes back — high signal, low noise.
4. A Unified View
We can frame the entire agent architecture as an optimization problem:
Maximize prompt relevance (First Law) subject to a context budget (Second Law).
The hierarchy of mechanisms described in Section 3 represents different points on the relevance-versus-cost tradeoff curve:
| Layer | Always in Context? | Context Cost | Relevance | Example |
|---|---|---|---|---|
| System Prompt | Yes | Low (compact) | High (curated) | Role, safety rules, output format |
| Skills | On trigger | Medium | Very High | SKILL.md for testing, blog writing |
| Tool Results | On demand | Variable | High (targeted) | File contents, search results |
| Memory | On query | Low–Medium | Medium–High | User prefs, repo conventions |
| Subagent Results | On completion | Low (summary) | High (distilled) | Codebase exploration findings |
Reading from top to bottom, the pattern is clear: keep the always-on context lean and curated; push everything else to on-demand retrieval. Each layer exists because it offers a favorable tradeoff between the information it provides and the context it consumes.
Future advances — longer context windows, more efficient attention mechanisms, better retrieval models — will shift the specific tradeoff points. A model with a 10-million-token context window can afford to include more background material. Sparse attention architectures may reduce the “lost in the middle” penalty. But the fundamental tension between the two laws will remain: there will always be more potentially-relevant information than context capacity, and the architectural response will always be some form of hierarchical, on-demand context management.
5. Returning to Karpathy’s List
With the two laws in hand, we can revisit that daunting catalog of concepts — agents, subagents, prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations — and see that they are not arbitrary. Each concept exists to serve one or both laws:
- Prompts, skills, hooks, modes → mechanisms for refining what the model sees (First Law).
- Contexts, memory, subagents → mechanisms for managing how much the model sees (Second Law).
- Tools, MCP, LSP, plugins → mechanisms for fetching precise information on demand instead of pre-loading it (both laws simultaneously).
- Workflows, permissions, IDE integrations → orchestration layer that ensures the right mechanism fires at the right time.
The zoo is large, but it is not a random collection. Every animal in it is an adaptation to the same pair of environmental pressures.
6. Conclusion
The two laws of agent systems are not physical laws — they carry no mathematical proof and admit exceptions. The individual observations behind them are well-established: that few-shot learning outperforms zero-shot has been documented since the GPT-3 paper2, and the “lost in the middle” phenomenon has been studied in detail by Liu et al.6 and others. What I am proposing here is not a new empirical discovery but a synthesis — a framing that unifies these known facts into a pair of competing constraints whose tension explains why agent systems are architecturally structured the way they are. As far as I can tell from surveying the literature — including Lilian Weng’s comprehensive agent overview11, Anthropic’s guide on building effective agents12, and the major LLM agent survey by Xi et al.13 — this specific “two laws” framing has not been previously articulated.
The First Law (better prompts yield better outputs) drives the entire enterprise — agents exist to construct prompts that a human user would not bother to assemble. The Second Law (context dilution degrades performance) constrains how that construction is done — you cannot simply throw everything into the window and hope for the best.
Every architectural choice in a modern agent system — from skills to tools to memory tiers to subagents — is a specific answer to the question: how do we maximize the signal in the context while minimizing the noise? Understand the constraints, and the architecture follows naturally.
Cited as:
Tang, Yanfei. (Apr 2026). “Two Laws of Agent Systems. https://yanfeit.github.io/agent_laws/.
Or
@article{tang2026twolaws,
title = "Two Laws of Agent Systems",
author = "Tang, Yanfei",
year = "2026",
month = "Apr",
url = "https://yanfeit.github.io/agent_laws/"
}
-
Karpathy, A. Post on X (formerly Twitter), February 2025. https://x.com/karpathy/status/2004607146781278521 ↩
-
Brown, T. B. et al. Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems 33, 1877–1901 (2020). arXiv:2005.14165 ↩ ↩2
-
Wei, J. et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems 35, 24824–24837 (2022). arXiv:2201.11903 ↩
-
Lewis, P. et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems 33, 9459–9474 (2020). arXiv:2005.11401 ↩
-
Kamradt, G. Needle In A Haystack — Pressure Testing LLMs. https://github.com/gkamradt/LLMTest_NeedleInAHaystack (2023). ↩
-
Liu, N. F. et al. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics 12, 157–173 (2024). arXiv:2307.03172 ↩ ↩2
-
Hsieh, C.-Y. et al. RULER: What’s the Real Context Size of Your Long-Context Language Models? arXiv preprint arXiv:2404.06654 (2024). arXiv:2404.06654 ↩
-
Schick, T. et al. Toolformer: Language Models Can Teach Themselves to Use Tools. Advances in Neural Information Processing Systems 36 (2023). arXiv:2302.04761 ↩
-
Yao, S. et al. ReAct: Synergizing Reasoning and Acting in Language Models. International Conference on Learning Representations (2023). arXiv:2210.03629 ↩
-
Anthropic. Model Context Protocol Specification. https://modelcontextprotocol.io/ (2024). ↩
-
Weng, L. LLM-powered Autonomous Agents. Lil’Log (June 2023). https://lilianweng.github.io/posts/2023-06-23-agent/ ↩
-
Anthropic. Building Effective Agents. Anthropic Engineering Blog (December 2024). https://www.anthropic.com/engineering/building-effective-agents ↩
-
Xi, Z. et al. The Rise and Potential of Large Language Model Based Agents: A Survey. arXiv preprint arXiv:2309.07864 (2023). arXiv:2309.07864 ↩