CUDA是目前比较流行的高性能计算的开发工具之一,这种编程模式涉及了CPU+GPU的异构计算。
我花了一些时间来阅读CUDA编程的两本书,一本是樊哲勇的《CUDA 编程:基础与实践》(书A)1,一本是Brian Tuomanen的《GPU编程实战:基于Python和CUDA》(书B)2。这篇博客的主要内容是将书A中的CUDA C编程应用于书B的案例,采用的案例就是Manderbrot图。
首先,先说明一下产生Manderbrot集合的算法。对于给定的复数,$c$,定义循环序列
\[\begin{gathered} z_0 = 0, \quad n = 0 \\ z_n = z_{n-1}^2 + c, \quad n \ge 0 \end{gathered}\]当 $n$ 趋向于无穷大是,$|z_n|$ 的上界为2,那么我们定义复数 $c$ 是Manderbrot集合的成员。为了找到了这样的集合,我们可以设计如下的算法,
def simple_mandelbrot(width, height, real_low, real_high, imag_low, imag_high, max_iters, upper_bound):
real_vals = np.linspace(real_low, real_high, width)
imag_vals = np.linspace(imag_low, imag_high, height)
# we will represent members as 1, non-members as 0.
mandelbrot_graph = np.ones((height,width), dtype=np.float32)
for x in range(width):
for y in range(height):
c = np.complex64( real_vals[x] + imag_vals[y] * 1j )
z = np.complex64(0)
for i in range(max_iters):
z = z**2 + c
if(np.abs(z) > upper_bound):
mandelbrot_graph[y,x] = 0
break
return mandelbrot_graph
上面是一个简单的串行的程序,下面我们将用CUDA C改写称为一个高性能的CUDA程序。一个典型而简单的CUDA程序结构具有如下的形式:
int main(void)
{
// 主机代码
// 核函数调用
// 主机代码
return 0;
}
__global void func_from_gpu()
{
// 核函数代码
}
主机(host)代码包含从主机传输数据到设备(device)的代码,这里说的设备就是GPU加速卡。核函数调用是使用设备进行数据计算。计算完毕后,就可以把数据从设备上拷贝回主机进行后处理和缓存释放。核函数的声明与定义必须被限定词 __global__ 修饰。以下是一个核函数的声明和定义的示例,
__global__ void mandel(const double *real_vals, const double *imag_vals, int *mandelbrot_graph);
// 主机代码内的调用方式
mandel<<<grid_size, block_size>>>(d_real_vals, d_imag_vals, d_mandelbrot_graph);
主机代码调用核函数最大的特点就是一对三括号 <<<grid_size, block_size>>>,主要是告诉设备需要多少个线程和排列情况的。grid_size 是指网格大小,可以认为是线程块的个数,block_size 是指线程块大小,可以认为是每个线程块中的线程数,如图1所示。
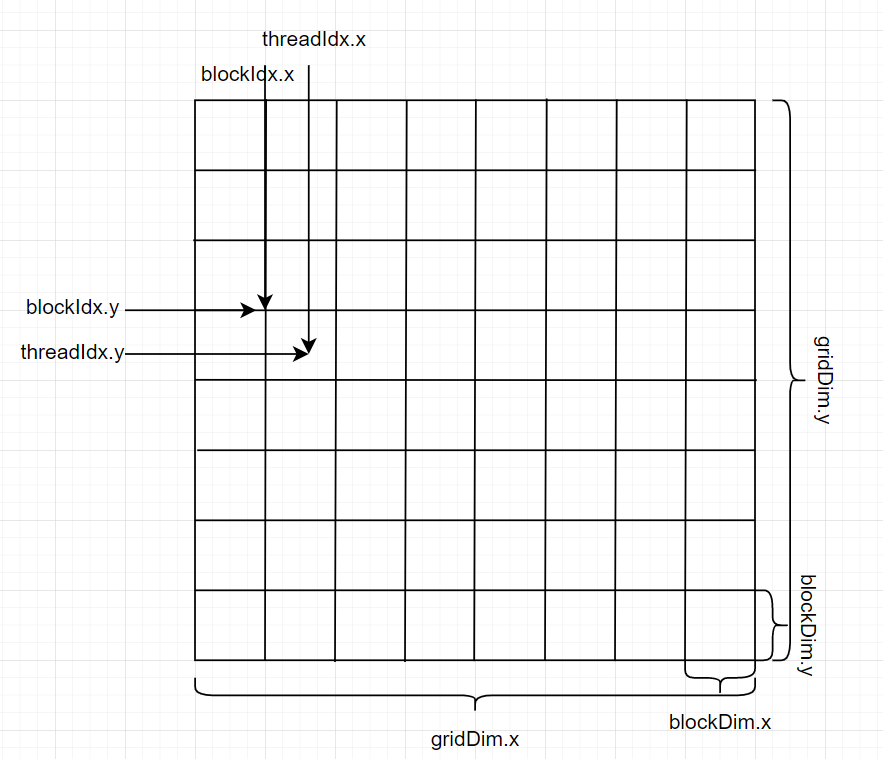 图. 1 CUDA线程块
图. 1 CUDA线程块
网格大小和线程块大小可以是三维的,可以在主机代码中采用结构体dim3定义三维的网格和线程块,例如,
const int width = 512;
const int height = 512;
const int maxt = 32;
const dim3 grid_size(width/maxt, height/maxt, 1);
const dim3 block_size(maxt, maxt, 1);
在核函数定义中,内建变量只在核函数中有效。gridDim和blockDim是类型为dim3的变量,代表从主机代码传入的参数网格大小和线程块个数。blockIdx和threadIdx是类型为uint3的变量,代表网格的索引和线程的索引,并且满足如下的关系:
- blockIdx.x 的取值范围是从 0 到 gridDim.x - 1。
- blockIdx.y 的取值范围是从 0 到 gridDim.y - 1。
- blockIdx.z 的取值范围是从 0 到 gridDim.z - 1。
- threadIdx.x 的取值范围是从 0 到 blockDim.x - 1。
- threadIdx.y 的取值范围是从 0 到 blockDim.y - 1。
- threadIdx.z 的取值范围是从 0 到 blockDim.z - 1。
同时CUDA中对能够定义的网格大小和线程块大小做了限制。对于从开普勒和安培架构的GPU来说,网格大小在x、y和z这3个方向的最大允许值分别为 $2^{31}-1$ 、$65535$ 和 $65535$。而线程块的大小在x、y和z这3个方向的最大允许值分别为 $1024$ 、$1024$ 和 $64$,并且要求了总线程块的大小不能大于 $1024$。通过主机代码对核函数的调用会指派很多线程。核函数的编写就需要关注到线程的标识与计算区域的对应关系即可。
__global__ void mandel(const double *real_vals, const double *imag_vals, int *mandelbrot_graph)
{
const int i = blockDim.x * blockIdx.x + threadIdx.x;
const int j = blockDim.y * blockIdx.y + threadIdx.y;
const int _X = blockDim.x * gridDim.x;
double z_real = 0.0;
double z_imag = 0.0;
double z_real_new = 0.0;
double z_imag_new = 0.0;
double c_real = real_vals[i];
double c_imag = imag_vals[j];
for (int k = 0; k < max_iters; k++)
{
z_real_new = z_real*z_real - z_imag*z_imag + c_real;
z_imag_new = 2 *z_real*z_imag + c_imag;
z_real = z_real_new;
z_imag = z_imag_new;
if (sqrt(z_real*z_real + z_imag*z_imag) > upper_bound){
mandelbrot_graph[i + _X*j] = 0;
break;
}
}
}
主函数以及一些全局变量的定义为,
#include <stdio.h>
#include <cmath>
#include <complex>
#include <ctime>
#include "error.cuh"
using namespace std;
const int width = 512;
const int height = 512;
const int max_iters = 256;
const double upper_bound = 2.5;
const double real_low = -2;
const double real_high = 2;
const double imag_low = -2;
const double imag_high = 2;
const int maxt = 32;
__global__ void mandel(const double *real_vals, const double *imag_vals, int *mandelbrot_graph);
int main(void)
{
int *mandelbrot_graph = (int*) malloc(sizeof(int) * width * height);
double *real_vals = (double*) malloc(sizeof(double) * width);
double *imag_vals = (double*) malloc(sizeof(double) * height);
const dim3 grid_size(width/maxt, height/maxt, 1);
const dim3 block_size(maxt, maxt, 1);
clock_t start;
clock_t end;
// initialization
for (int i = 0; i < width; i++)
{
real_vals[i] = real_low + (real_high - real_low) * i/(width - 1);
}
for (int i = 0; i < height; i++)
{
imag_vals[i] = imag_low + (imag_high - imag_low) * i/(height - 1);
}
for (int i = 0; i < height; i++)
{
for (int j = 0; j < width; j++)
{
mandelbrot_graph[i*width+j] = 1;
}
}
// copy data from host to device
double *d_real_vals, *d_imag_vals;
int *d_mandelbrot_graph;
start = clock();
cudaMalloc((void **)&d_real_vals, sizeof(double) * width);
cudaMalloc((void **)&d_imag_vals, sizeof(double) * height);
cudaMalloc((void **)&d_mandelbrot_graph, sizeof(int) * width * height);
end = clock();
double elapsed_time = (double(end - start))/CLOCKS_PER_SEC*1000;
printf("CUDA Memory Init takes %f ms\n", elapsed_time);
start = clock();
CHECK(cudaMemcpy(d_real_vals, real_vals, width*sizeof(double), cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_imag_vals, imag_vals, height*sizeof(double), cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_mandelbrot_graph, mandelbrot_graph, width*height*sizeof(int), cudaMemcpyHostToDevice));
end = clock();
elapsed_time = (double(end - start))/CLOCKS_PER_SEC*1000;
printf("CUDA Memory copy from host to device take %f ms\n", elapsed_time);
start = clock();
mandel<<<grid_size, block_size>>>(d_real_vals, d_imag_vals, d_mandelbrot_graph) ;
cudaDeviceSynchronize();
end = clock();
elapsed_time = (double(end - start))/CLOCKS_PER_SEC*1000;
printf("CUDA Mandelbrot graph computation & Sync takes %f ms\n", elapsed_time);
start = clock();
cudaMemcpy(mandelbrot_graph, d_mandelbrot_graph, width*height*sizeof(int), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
end = clock();
elapsed_time = (double(end - start))/CLOCKS_PER_SEC*1000;
printf("CUDA copy from device to host & Sync %f ms\n", elapsed_time);
// write data to file
start = clock();
FILE *ifile = fopen("mandelbrot0.txt", "w");
for (int i = 0; i < height; ++i)
{
for (int j = 0; j < width; ++j)
{
fprintf(ifile, "%d ", mandelbrot_graph[i*width+j]);
}
fprintf(ifile, "\n");
}
end = clock();
elapsed_time = (double(end - start))/CLOCKS_PER_SEC*1000;
printf("Write file takes %f ms\n", elapsed_time);
// free memory
start = clock();
fclose(ifile);
free(real_vals);
free(imag_vals);
free(mandelbrot_graph);
cudaFree(d_real_vals);
cudaFree(d_imag_vals);
cudaFree(d_mandelbrot_graph);
end = clock();
elapsed_time = (double(end - start))/CLOCKS_PER_SEC*1000;
printf("Free memory takes %f ms\n", elapsed_time);
return 0;
}
// error.cuh
#pragma once
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
cudaMalloc是在设备中分配内存,cudaMemcpy是内存和设备内存之间的传输,cudaFree是设备内存释放。