Previously, we discussed about the CUDA language to increase performance of code by GPU. We give a very simple example to acceralte code of drawing a Mandelbrot graph. However, even for this simple example, it required quite efforts. Therefore, programmer desire the ability to apply with a familiar, high level programming model that provide both high performace and simpilicity. OpenACC is a programming model that uses high-level compiler directives to parallel the code for a variety of hardware accelerators. This post gives some examples to use OpenACC in practice.
The OpenACC Accelerator Model
The OpenACC accelerator model is an add-on device model, see Figure 1. The OpenACC offload both the computation and data from a host device to an accelerator device. Typically, the host device contains CPU and DDR momery. While, the accelerator device is normally a GPU and GPU memories. Broadly speaking, OpenACC does support the same archtecture for both the host and device. More information about OpenACC tutorial can be found on the website1. (WARNING: This post largely quotes reference 1 and 2)
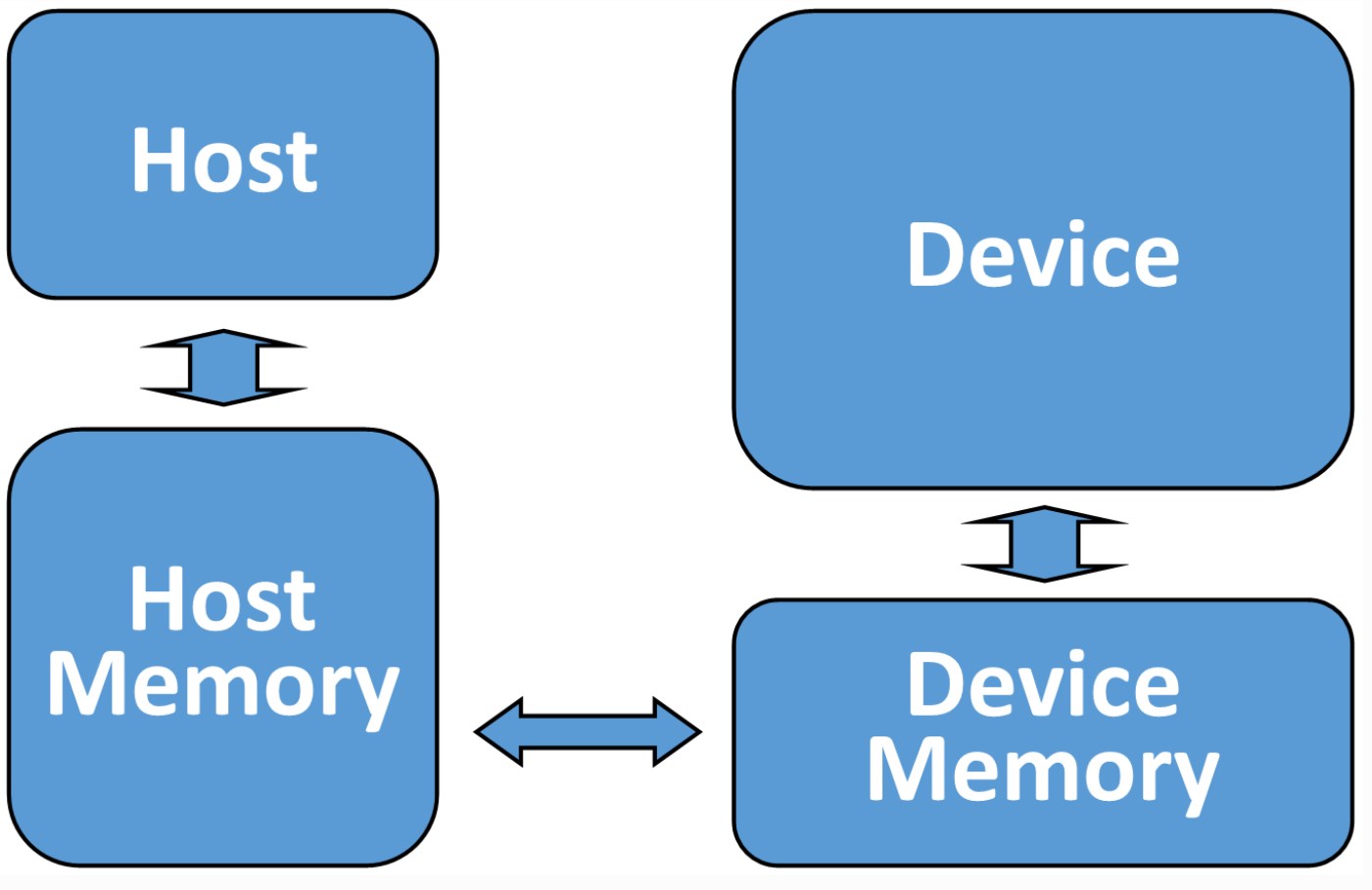 Fig.1 OpenACC accelerator model.
Fig.1 OpenACC accelerator model.
Compiler code with OpenACC
There are several choices of OpenACC compilers, PGI (acquired by Nvidia in 2013), GCC and Nvidia’s nvc. We will choose nvc compiler in the following cases. We can show the suggested flags for OpenACC from the makefiles for nvc compilers. The case that we are using are from the HPC book2.
default: StreamTriad
all: StreamTriad
CC=nvc
CFLAGS:= -g -O3 -acc -fast -Minfo=accel
%.o: %.c
${CC} ${CFLAGS} -c $^
StreamTriad: StreamTriad.o timer.o
${CC} ${CFLAGS} $^ -o StreamTriad
clean:
rm -f StreamTriad StreamTriad.o
rm -f timer.o
distclean:
rm -f Makefile
For nvc compiler, the flag to enable OpenACC compilation is -acc. The -Minfo=accel flag tells the compiler to provide feedback on acceleration directives. For the hardware information, we are using an Intel(R) Xeon(R) Gold 5220R CPU @ 2.20GHz and Nvidia RTX A5000 GPU. There are two pragma directives to tell the compiler to load the loop computation from host to device, pragma acc kernels and pragma acc parallel. Below, we list the benchmark results from OpenACC stream triad optimization.
| OpenACC stream triad kernel run time (ms) | |
|---|---|
| Serial CPU code | 35.9 |
| Kernel 1. Fails to parallelize loop | 2596 |
| Kernel 2. Adds restrict notation | 101.6 |
| Kernel 3. Adds dynamic data region | 0.718 |
| Parallel 1. Adds compute region | 102.5 |
| Parallel 2. Adds structured data region | 0.719 |
| Parallel 3. Adds dynamic data region | 0.719 |
| Parallel 4. Allocates data only on device | 0.717 |
Using the kernels progma to get auto-parallelization from the compiler
The kernels pragma is often used first to get feedback from the compiler on a section of code. We can list the specification for the kernels pragma from the OpenACC 2.6 standard:
#pragma acc kernels [data clause | kernel optimization | async clasu | conditional ]
where
data clauses - [ copy | copyin | copyout | create | no_create | present | deviceptr | attach | default (one|present) ]
kernel optimization = [ num_gangs | num_workers | vector_length | device_type | self ]
async clauses - [ async | wait ]
conditional - [ if ]
The usage of the specification is discussed later. We can first start with a default directive for the targeted block of for loop.
// Kernel 1
#include <stdio.h>
#include <stdlib.h>
#include "timer.h"
int main(int argc, char *argv[]){
int nsize = 200000000, ntimes=16;
double* a = malloc(nsize * sizeof(double));
double* b = malloc(nsize * sizeof(double));
double* c = malloc(nsize * sizeof(double));
struct timespec tstart;
// initializing data and arrays
double scalar = 3.0, time_sum = 0.0;
#pragma acc kernels
for (int i=0; i<nsize; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int k=0; k<ntimes; k++){
cpu_timer_start(&tstart);
// stream triad loop
#pragma acc kernels
for (int i=0; i<nsize; i++){
c[i] = a[i] + scalar*b[i];
}
time_sum += cpu_timer_stop(tstart);
}
printf("%lf", c[0]);
printf("Average runtime for stream triad loop is %lf secs\n", time_sum/ntimes);
free(a);
free(b);
free(c);
return(0);
}
The following output shows the feedback from the Nvidia nvc compiler:
nvc -g -O3 -acc -fast -Minfo=accel -c StreamTriad_kern1.c
main:
14, Generating implicit copyout(b[:200000000],a[:200000000]) [if not already present]
16, Loop is parallelizable
Generating NVIDIA GPU code
16, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
22, Generating implicit copyout(c[:200000000]) [if not already present]
Generating implicit copyin(b[:200000000],a[:200000000]) [if not already present]
25, Complex loop carried dependence of b->,a-> prevents parallelization
Loop carried dependence of c-> prevents parallelization
Loop carried backward dependence of c-> prevents vectorization
Accelerator serial kernel generated
Generating NVIDIA GPU code
25, #pragma acc loop seq
25, Complex loop carried dependence of b->,a-> prevents parallelization
Loop carried dependence of c-> prevents parallelization
Loop carried backward dependence of c-> prevents vectorization
The above information tells the programmer that the compiler can not automatically parallelize the loop. The simplest fix is to add a restrict attribute to the declaration of pointer variable a, b , and c.
// Kernel 2:
#include <stdio.h>
#include <stdlib.h>
#include "timer.h"
int main(int argc, char *argv[]){
int nsize = 200000000, ntimes=16;
double* restrict a = malloc(nsize * sizeof(double));
double* restrict b = malloc(nsize * sizeof(double));
double* restrict c = malloc(nsize * sizeof(double));
struct timespec tstart;
// initializing data and arrays
double scalar = 3.0, time_sum = 0.0;
#pragma acc kernels
for (int i=0; i<nsize; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int k=0; k<ntimes; k++){
cpu_timer_start(&tstart);
// stream triad loop
#pragma acc kernels
for (int i=0; i<nsize; i++){
c[i] = a[i] + scalar*b[i];
}
time_sum += cpu_timer_stop(tstart);
}
printf("Average runtime for stream triad loop is %lf secs\n", time_sum/ntimes);
free(a);
free(b);
free(c);
return(0);
}
For this case, the compiler successfully parallelizes the for loop code. However, we can see that the runtime is longer than the serial code. This is because the data movement between the host memory and device memory takes time. It is quite often that the process of copying data from the host to the accelerator and back will be more costly than the computation itsel. Therefore, we shall reduce the data movement in order to speed up the overall runtime. To improve upon this, we’ll exploit the data locality of the application. Data locality means that data used in device or host memory should remain local to that memory for as long as it’s needed. The data construct facilitates the sharing of data between multiple parallel regions. A data region may be added around one or more parallel regions in the same function or may be placed at a higher level in the program call tree to enable data to be shared between regions in multiple functions. Below is an example to use dynamics data construct which will be explained in the latter case.
// Kernel 3:
#include <stdio.h>
#include <stdlib.h>
#include "timer.h"
int main(int argc, char *argv[]){
int nsize = 200000000, ntimes=16;
double* restrict a = malloc(nsize * sizeof(double));
double* restrict b = malloc(nsize * sizeof(double));
double* restrict c = malloc(nsize * sizeof(double));
#pragma acc enter data create(a[0:nsize],b[0:nsize],c[0:nsize])
struct timespec tstart;
// initializing data and arrays
double scalar = 3.0, time_sum = 0.0;
#pragma acc kernels present(a[0:nsize],b[0:nsize])
for (int i=0; i<nsize; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int k=0; k<ntimes; k++){
cpu_timer_start(&tstart);
// stream triad loop
#pragma acc kernels present(a[0:nsize],b[0:nsize],c[0:nsize])
for (int i=0; i<nsize; i++){
c[i] = a[i] + scalar*b[i];
}
time_sum += cpu_timer_stop(tstart);
}
printf("Average runtime for stream triad loop is %lf secs\n", time_sum/ntimes);
#pragma acc exit data delete(a[0:nsize],b[0:nsize],c[0:nsize])
free(a);
free(b);
free(c);
return(0);
}
Use the Parallel Loop Pragma for More Control Over Parallelization
The parallel loop pragma is recommended to use in the application according to the reference2. It is more consistent with the form used in other parallel languages such as OpenMP. It also generates more consistent and portable performance across compilers. The parallel loop pragma is actually two separate directives. The first is the parallel directive that opens a parallel region. The second is the loop pragma that distributes the work across the parallel work elements. The parallel pragma take the following specification.
#pragma acc parallel [ clause ]
data clause - [ reduction | private | firstprivate | copy |
copyin | copyout | create | no_create | present |
deviceptr | attach | default (none|present) ]
kernel optimization - [ num_gangs | num_workers |
vector_length | device_type | self ]
async clauses - [ async | wait ]
conditional - [ if ]
The loop pragma is added in the clause. The default mode is to parallelize the loop interation. The following code has likely slowed down due to the data movement.
// Parallel 1:
#include <stdio.h>
#include <stdlib.h>
#include "timer.h"
int main(int argc, char *argv[]){
int nsize = 200000000, ntimes=16;
double* a = malloc(nsize * sizeof(double));
double* b = malloc(nsize * sizeof(double));
double* c = malloc(nsize * sizeof(double));
struct timespec tstart;
// initializing data and arrays
double scalar = 3.0, time_sum = 0.0;
#pragma acc parallel loop
for (int i=0; i<nsize; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int k=0; k<ntimes; k++){
cpu_timer_start(&tstart);
// stream triad loop
#pragma acc parallel loop
for (int i=0; i<nsize; i++){
c[i] = a[i] + scalar*b[i];
}
time_sum += cpu_timer_stop(tstart);
}
printf("Average runtime for stream triad loop is %lf secs\n", time_sum/ntimes);
free(a);
free(b);
free(c);
return(0);
}
A further optimization can be the structured data region that tells the compiler that the array does not need to move around between host and device.
// Parallel 2:
#pragma acc data create(a[0:nsize],b[0:nsize],c[0:nsize])
{
#pragma acc parallel loop present(a[0:nsize],b[0:nsize])
for (int i=0; i<nsize; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int k=0; k<ntimes; k++){
cpu_timer_start(&tstart);
// stream triad loop
#pragma acc parallel loop present(a[0:nsize],b[0:nsize],c[0:nsize])
for (int i=0; i<nsize; i++){
c[i] = a[i] + scalar*b[i];
}
time_sum += cpu_timer_stop(tstart);
}
printf("Average runtime for stream triad loop is %lf secs\n", time_sum/ntimes);
} //#pragma end acc data block(a[0:nsize],b[0:nsize],c[0:nsize])
For a more flexible usage, OpenACC has dynamics data regions to address the issues of memory allocations in object-oriented code. The dynamic data region construct was specifically created for more complex data management scenarios, such as constructors and destructors in C++. Rather than using scoping braces to define the data region, the pragma has an enter and exit clause:
#pragma acc enter data
#pragma acc exit data
For the exit data directive, there is an additional delete clause that we can use. This use of the enter/exit data directive is best done where allocations and deallocations occur. The enter data directive should be placed just after an allocation, and the exit data directive should be inserted just before the deallocation.
#include <stdio.h>
#include <stdlib.h>
#include "timer.h"
int main(int argc, char *argv[]){
int nsize = 200000000, ntimes=16;
double* restrict a = malloc(nsize * sizeof(double));
double* restrict b = malloc(nsize * sizeof(double));
double* restrict c = malloc(nsize * sizeof(double));
#pragma acc enter data create(a[0:nsize],b[0:nsize],c[0:nsize])
struct timespec tstart;
// initializing data and arrays
double scalar = 3.0, time_sum = 0.0;
#pragma acc parallel loop present(a[0:nsize],b[0:nsize])
for (int i=0; i<nsize; i++) {
a[i] = 1.0;
b[i] = 2.0;
}
for (int k=0; k<ntimes; k++){
cpu_timer_start(&tstart);
// stream triad loop
#pragma acc parallel loop present(a[0:nsize],b[0:nsize],c[0:nsize])
for (int i=0; i<nsize; i++){
c[i] = a[i] + scalar*b[i];
}
time_sum += cpu_timer_stop(tstart);
}
printf("Average runtime for stream triad loop is %lf secs\n", time_sum/ntimes);
#pragma acc exit data delete(a[0:nsize],b[0:nsize],c[0:nsize])
free(a);
free(b);
free(c);
return(0);
}
If we paid close attention to the previous example, we will have noticed that the arrays a, b, and c are allocated on both the host and the device, but are only used on the device. We show one way to fix this by using the acc_malloc routine and then putting the deviceptr clause on the compute regions.
#include <stdio.h>
#include <openacc.h>
#include "timer.h"
int main(int argc, char *argv[]){
int nsize = 200000000, ntimes=16;
double* restrict a_d = acc_malloc(nsize * sizeof(double));
double* restrict b_d = acc_malloc(nsize * sizeof(double));
double* restrict c_d = acc_malloc(nsize * sizeof(double));
struct timespec tstart;
// initializing data and arrays
const double scalar = 3.0;
double time_sum = 0.0;
#pragma acc parallel loop deviceptr(a_d,b_d)
for (int i=0; i<nsize; i++) {
a_d[i] = 1.0;
b_d[i] = 2.0;
}
for (int k=0; k<ntimes; k++){
cpu_timer_start(&tstart);
// stream triad loop
#pragma acc parallel loop deviceptr(a_d,b_d,c_d)
for (int i=0; i<nsize; i++){
c_d[i] = a_d[i] + scalar*b_d[i];
}
time_sum += cpu_timer_stop(tstart);
}
printf("Average runtime for stream triad loop is %lf secs\n", time_sum/ntimes);
acc_free(a_d);
acc_free(b_d);
acc_free(c_d);
return(0);
}
The data movement is eliminated and memory requirements on the host reduced.
This post only covers a small set of OpenACC standards. More information should be refered to HPC book and OpenACC website.